
この度HOMENOC/AS59105の監視基盤をリニューアルいたしました。今回はそれらについてご紹介します。
Home NOCマネジメントネットワーク
Home NOCのマネジメントネットワークはこのようになっています。ASネットワークとは完全に分離がされており、ASネットワークに障害が発生しても管理コンソールは掴むことのできるように設計がされています。監視基盤はこのNW上に乗ることになります。
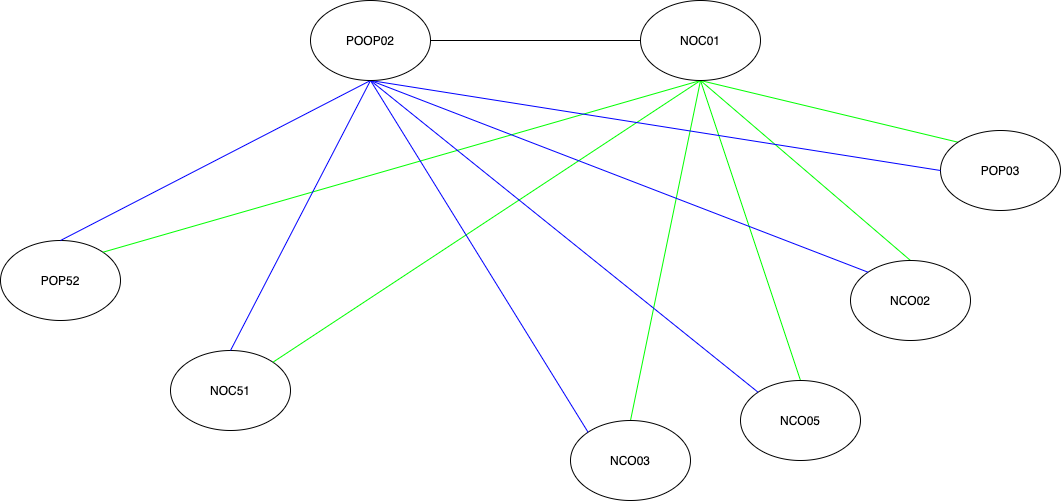
リニューアル前と問題
リニューアル前はLibreNMSとGRIによりメトリクスを収集していました。しかし、構築から時間が経ちメンテナーが不在となり放置される状況が長らく続き、HOMENOCで6月に発生した障害のまとめが発生しました。これらの問題を解消するために監視基盤のリニューアルを行いました。
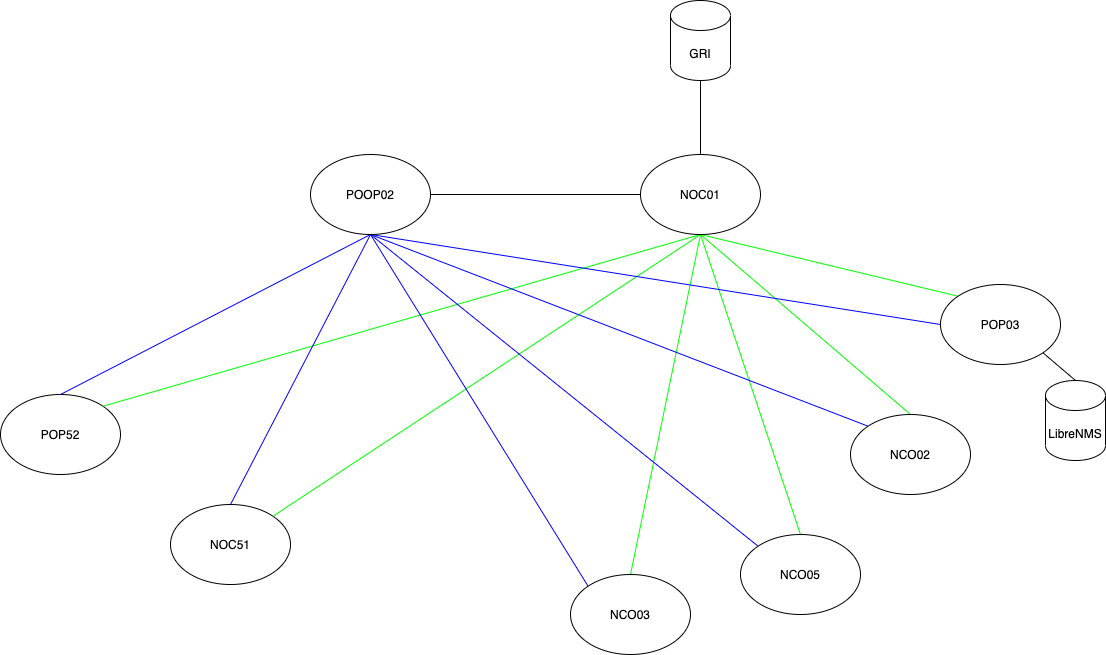
リニューアル後
リニューアルのためにまずは監視を行うソフトウェアの選定から行いました。選定を行う上で必要な要件を洗い出すと以下の点がありました。
- Slackへの通知が容易であること。
- プライベートMIBの追加が比較的容易であること。
- ドキュメントが充実していること。
- 自動化や省力化が可能であること。
- 使いやすいこと。
1.については当団体の日常的なコミュニケーションはSlackで行われていることが主な理由です。こちらに関してはWebhookが使えるものであれば満たすことはできます。
2.についてはL2トンネルの終端ルータとしてNEC UNIVERGEシリーズを利用していることが主な理由です。インターフェイスのトラフィック情報は標準のifMIBに定義がされているため殆どは問題がありませんが、CPUやメモリの使用率はプライベートMIBの場合が多いです。
残りの3~5については監視基盤を構築する上で一番に重要なことだと筆者は考えています。多くのメトリクスが何もせずとも取得できる監視のソフトウェアがあってもそのソフトウェアをメンテナンスできるメンバーが1人しか居なければそれはそのチームにとっては適切なソフトウェアではありません。
これらの要件と監視ソフトウェア宗教を加味した結果Zabbixを選定しました。
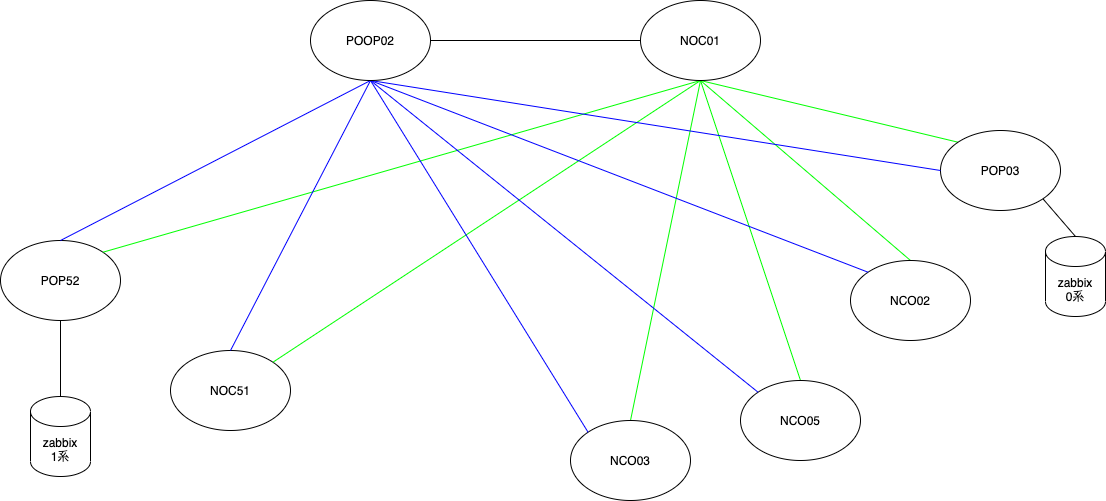
最終的な構成は以下のような形です。当初はリニューアル前と同様にPOP03(東日本エリア)のみの設置でしたが、東西冗長やそもそも監視生きてる?問題に対処を行うためにPOP03(東日本)とPOP52(西日本)のActive-Active構成となりました。また、東西分散冗長を行う上で意識したこととしてはActive-Activeで構築を行うことです。Active-Activeの構成にすることで両系のZabbixが互いの監視を行いサーバの正常性を逐次監視ができます。ネットを検索するとActive-Standbyの構成は多くヒットしますが、Active-Activeでの構成はなかなかヒットしません。そのため、主系のZabbixで障害が起こったときのみ副系がAlert機能を引き継ぐよう構築を行いました。中身はAPI経由でActionをオンオフにするスクリプトです。
Zabbix公式でActive-Active構成用のツールはあるようですが、Enterpriseになるのかよくわからなかったので今回はこのような構成で構築を行いました。
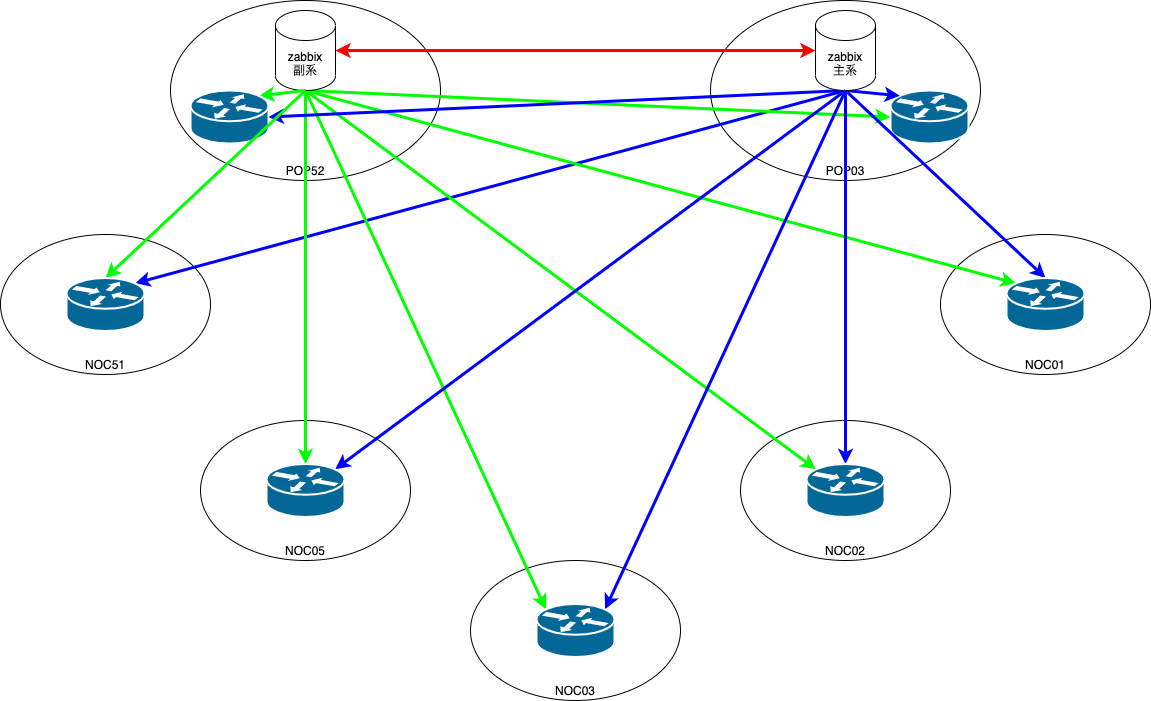
Zabbix Serverから各拠点への監視は以下の図がわかりやすいです。このような構成であればProxyを挟むことが推奨されますが、Home NOCではサーバ障害でデバイスへの監視が損なわれる点や監視のPollingで問題があった際のトラブルシューティング簡素化のためにサーバから直でデバイスの監視を行っています。幸いにもCPUやメモリには余裕のあるインスタンスであったため現状では目立った問題は浮上しておりません。
監視基盤を構築後に待っている作業は監視項目の追加です。こちらはZabbixのLLD(Low-level Discovery)機能を使い自動的に登録を行いました。具体的には各拠点のマネジメントサブネットへ1時間に1回にLLD Pollerが周回を行い、ホストの追加(管理ホストの命名は逆引きから自動設定)とSysDescrの結果を元に基本的なTemplateの適用まで行っています。Home NOCではCisco,Juniper,NECなどの機器を運用しており、それらにあったTemplateの適用まで自動で行うことで最低限必要な情報はすぐに取得することができるようになっています。また登録漏れも最小限にすることができます。このような小さな簡略化も運用においては重要です。

運用を続けていく中でTemplateにはないけどMIBに定義があるアイテムが欲しくなることも多々あります。その場合はTemplateの自作や修正を行う必要も出てきます。Home NOCの場合ですと、そもそもUNIVERGE IXシリーズは出来合いのTemplateがざっと探す限り発見することができなかったため自作を行いました。こちらのTemplateはZabbix Share上に公開しているため、興味のある方はご利用ください。取得項目の追加希望はissueに記載いただくと製作者が対応するかもしれません。(しらんけど) -> NEC UNIVERGE IX
自作Templateで検出したnoc01itep01(BB区間用のIX)のファン故障
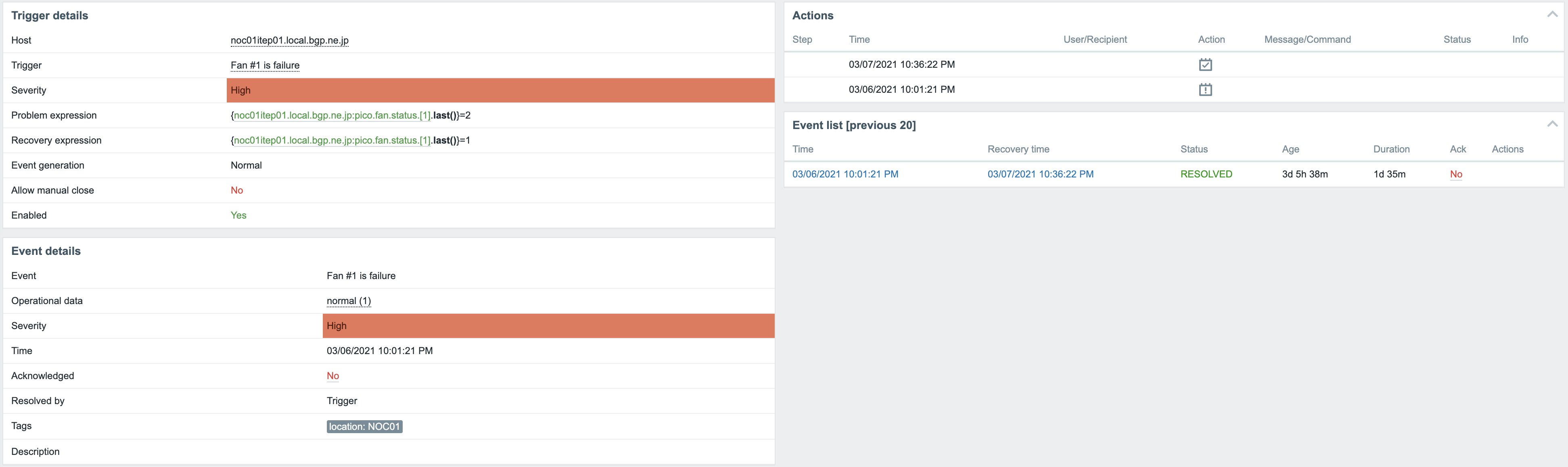
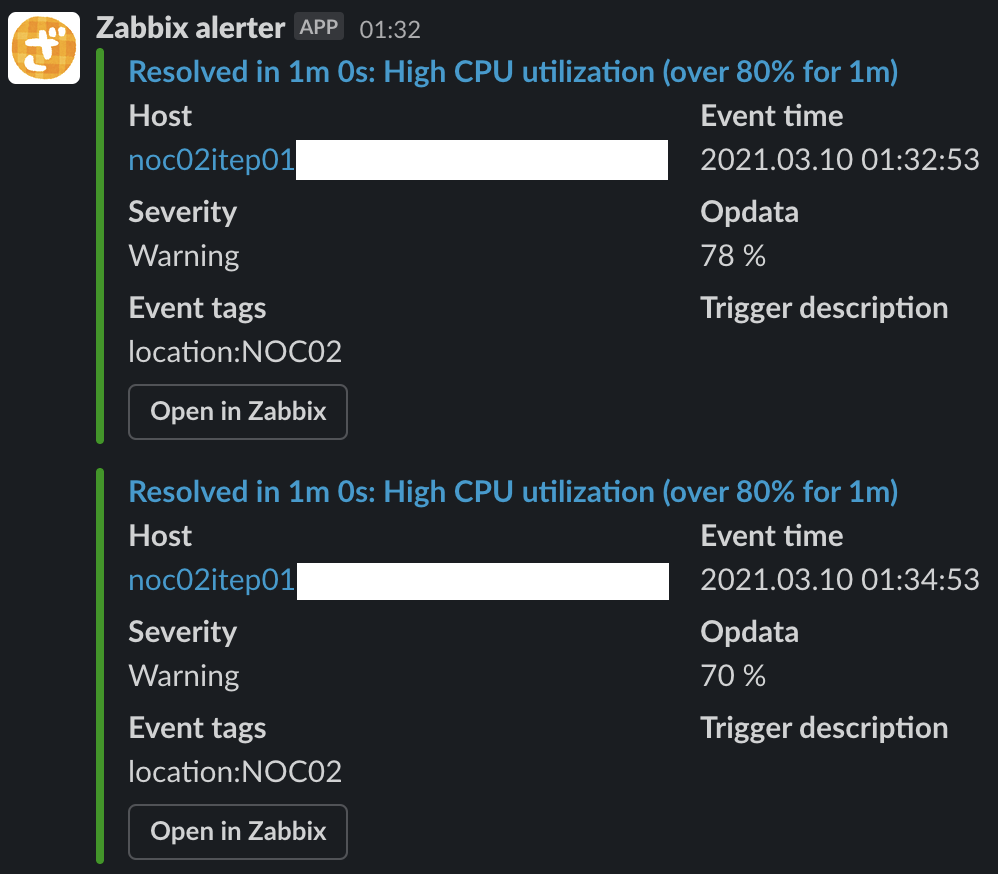
この監視基盤は構築から1ヶ月ほど経過し、もちろん健全に動作を続けています。おおよそ1日の障害検出数は13~14件ほどで大半はユーザBGPの断です。実際はユーザのBGP断は通知が上がってこないように予め抑止を掛けているのでSlackに流れるアラート件数は5~6件ほどです。その中でもCPU使用率高騰やI/Fへの大量トラフィックが大半を占めるので静観対応を行うことが多いです。
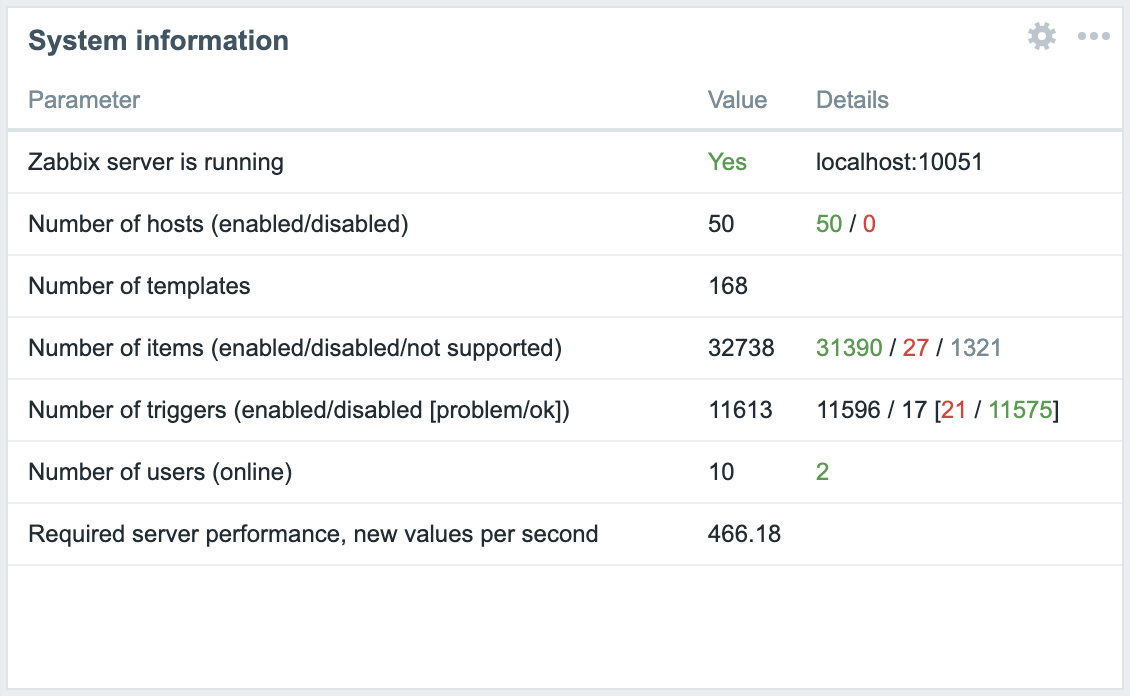
最終的なZabbixのSystem Informationは以下のようになりました。vpsが500を超えたあたりから運用負荷が上がるとの投稿もあるので気を引き締めて運用を続けていく必要がありそうです。
課題点
- 完全な冗長構成
- Zabbixは東西で分散冗長配置はされていますが、厳密に見るとソフトウェアバージョンやRDBMSレベルでは冗長化は施されておらず、もし特定条件下で停止しうる問題が発生したときは両系共に倒れる可能性が高いものとなっています。
- これは監視基盤の問題というより、OSの問題ですがUNIVERGE IXのifindexが動作中にコロコロと変わる問題があります。ifindexが変わるたびにZabbixでは新たなアイテムを追加し、StateをDownに設定するため無駄な通知が流れるといった状況があります。無駄or過剰な通知は本当に重要な通知の妨げになるため対応が必要です。
- ifindexを固定するコマンドはありますが、サブインターフェイスを含めすべて手動で設定をする必要があるかつ適用に再起動が必要なため現実的ではありません。
- DBのチューニング
お客様の中にMariaDBに詳しい方はいらっしゃいませんかー!?- 運用を続けていくと膨大なデータを瞬時に欲しいことが多々あります。それらの取得を行うときはDBから検索をかけることになりますが、実行に数十秒から数分かかるようではまともに使えるものではありません。また、Grafanaなどで可視化を行う際もDBへQuery処理が行われますがやはり瞬時に表示が行われる方がUXも良いです。
- メンテナンスの際の通知停止
- ZabbixにはMaintenance機能はありますが、BGPやIGPやトンネルI/Fを多数運用している我々では不便な箇所もあります。影響の出る範囲のホストをすべて停止を行うことでメンテナンス影響の想定内の通知は抑止することは可能ですが、想定外の通知も停止されてしまうため適切ではありません。通知停止を最低限にし、監視停止時間を最小限に利便性よく投入することができる対応も必要になります。
今後の運用
今後も安定したASを運用を続けるため、運用チームでは以下の検証や構築を進めています。
- ASネットワークの品質監視
- AS内外からのNWの品質計測を行い、トラブルシューティングの簡略化とそれらのデータを元にした品質の向上など。
- Openconfig/Telemetryへの対応
- 今後の監視の主流になるであろうOpenconfig/Telemetryへの対応も順次検証・対応を進めていきます。
所感
今回、リニューアルの構想から構築までは実際1週間足らずで完成することができました。当初は少し台数が多い程度でチューニング等は後から行えば良いと考えていたため、運用を開始してから想定以上の負荷でパラメーターチューニングで一時停止を何度か行いました。余裕を持った設計を行うことは重要と改めて感じることができました。 監視基盤の改修だけであればユーザの皆様はさほどメリットはないと感じられるかもしれませんが、ホームページへ新たに記載されたトラフィック情報(β)は同時期に構築したGrafanaのグラフから生成しており、以前のページに比べてより多くの情報をユーザの皆様へ提供することができるようになりました。